

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- jira
- pm
- 우아한형제들
- prd작성
- 결측치
- sql 예제
- SQL
- 소프트스킬
- kick-off
- pm아티클
- 내일배움캠프
- groupby
- 토스세션
- PRD
- FIGMA
- 데이터해석
- 그로스해킹
- 패러프레이징
- 와이어프레임
- 서비스정책서
- pm역량
- aarrr
- 당근마켓
- 데이터분석
- 스타트업
- orderby
- 문제정의
- mysql
- 서비스기획
- 도그냥
- Today
- Total
PM 다이어리
[내일배움캠프] PM - 서비스 기획 숙련 과제 회고 본문

미안하다, 강림이 좀 늦었다.
오랜만에 쓰는 TIL이다.
숙련과제 + 바로 이어지는 역기획 프로젝트로 인해 TIL를 쓸래야 쓸 수가 없었다 크크..
쓸 내용이 워낙 많으니 바로 가보자.
https://www.youtube.com/watch?v=0bTCIbyvBBc
<넬 (NELL) - 기억을 걷는 시간>
이 노래 모르는 사람 없게 해주세요.
엄청 유명한 노래인데, 요즘 오랜만에 들어보는 데 역시 명곡은 명곡인 이유가 있다.
지금 나와도 되게 트렌디하다고 생각할 것 같은 노래다.
📑 서비스 기획 숙련 과제 회고 링크
링크는 아래 남긴다.
https://www.notion.so/1ec359f63dae80d38b2fc104f58b077f
서비스 기획 숙련 과제 | Notion
1. 장바구니 전환율 분석 이유❔
www.notion.so
PDF로 뽑아보니 52장이 나오더라 ㅋㅋ;
노션에 분석 및 PRD 내용은 다 적혀있으니, 데이터 분석 과정에서 왜 내가 이렇게 했는지에 대한 내용을 위주로 적어보겠다.
1) 장바구니 전환율을 왜 분석하니? 🤔
과제에서는 장바구니 전환율을 분석하라고 던져주긴 했지만,
PM은 '이걸 왜 하지?'를 설득시키는 사람이다. 설득시키는 사람마저 이걸 왜 하는지 모르고 넘어가는 것은 어불성설이라 생각했다.
결국 PM은 비즈니스적 관점, 즉 서비스를 통한 '수익'을 내야하는 사람이다.
그렇기에 장바구니 전환을 통한 '구매 전환율' 상승과 연관지어야 봐야 한다고 생각하여 추가 분석을 진행했다.

2) 과제에서 준 페르소나를 왜 무시했니? 😐

과제에서는 이렇게 페르소나(사용자 유형) 4개를 주고 고르라고 했지만, 난 고르지 않고 진행했다.
청개구리 아니냐?
물론 저 페르소나 중 하나 택해서 진행해도 된다. 더 편하지.
그러나 첫째로 저 페르소나를 왜 준건지, 정말 의미있는 사용자 그룹이어서 준건지?도 모른채 선택해야 한다는 점과,
전체적인 분석 없이 바로 그룹을 좁혀서 분석을 진행했다간 편향적이며, 주관적인 나의 견해가 들어갈 수 있다는 위험성을 느꼈다.
그래서 힘들기야 하겠지만, 전체 데이터 분석 이후 과제에서 제시한 페르소나와 비교해보는 방식으로 분석을 진행했다.
3) 분석 방식이 왜 이래? 😫

컬럼들을 무슨 맥락으로 왜 이렇게 굳이 그룹화를 진행했냐?
1. 일단 기본적으론 필요없는 컬럼은 드랍해야 했다.
- 컬럼 수들이 너무 많고 어떤 게 의미있는 지 모르니까, 의미 없는 컬럼부터 제하면서 진행해야 했다.
2. 단순히 바로 분석을 진행하는 게 아닌, 컬럼 내부 및 외부 간 연관관계와 맥락을 파악해야 한다.
- 예를 들어 상품 카테고리는 당연히 상품 가격과 연관이 있어서 같이 묶거나 컬럼끼리 분석을 해야한다. 만약 상품끼리 묶었으면 다른 컬럼 및 그룹과의 다른 연관관계가 있는지도 살폈어야 했다. 그렇기에 그룹화는 필수적이었다.
- 그렇다면 그룹화는 어떤 기준으로 할거냐? 내가 상품 카테고리 x 상품 가격을 묶었듯, 서로 맥락이 연결되는 컬럼끼리 그룹화해서 묶어야 했다. 맥락을 어떻게 나눠 볼 건지에 대한 아이디어는 오로지 내 아이디어로, 일상에서 많이들 쓰는 '육하원칙'에서 착안해보는게 어떨까?하여 저렇게 나눠보았다. 결과적으로는 되게 잘 된 것 같았다.
1️⃣ 그룹 내 Columns 간 검증 ex) Who 그룹 내 ‘user_type’ x ‘traffic_source’ x 전환율
2️⃣ 그룹 간 Columns 교차 검증 ex) 'Who’ x ‘Where’ x 전환율
3️⃣ 그룹 간 Columns 다중 교차 검증 ex) ‘Who’ x ‘What’ x ‘How’ 전환율
요로코롬 분석을 진행했다. 교차 검증하다가 추가로 분석해야할 것 같은 놈들을 따로 모아서 다중 교차 검증을 하고, 거기서 또 추가 분석 해야 될 것 같으면 또또 검증하고.. 이렇게 했다.
4) Outlier를 왜 제거해야해? 🤨
컬럼들 중 유일하게 정수형 컬럼이 있었는데, 바로 '체류시간'이었다.

우리는 분석의 정답을 모른다. -> Supervised가 아닌, Clustering 분석을 진행해야 한다.
정답 데이터는 모르지만, 저 데이터만 보면 대충 어떻게 묶을지가 보이지 않나?

자. 이렇게 묶어볼 수 있겠다.
그럼 나머지 녀석들은? 데이터 표본수가 1000개인데 저 50개도 안되는 녀석들이 의미가 있는 데이터인가? 오히려 데이터 분석에 방해되는 데이터일 것이다.
자, 그렇다면 저 녀석들이 방해된다고 생각하고 다 제거했다고 가정해보자.
근데 저녀석들을 제거하면?

위 사진에서 볼 수 있듯 240s+ 이상인 체류시간 데이터는 다 지워지고, 180~240s 체류시간 데이터들도 영향을 받을 것이다.
그럼 180~240s 그룹도 의미가 없어지겠다. 데이터의 표본수가 없다 봐도 무방하고, 제거 이후 얘네도 Outlier로 볼 수 있을 것이다.
이렇게 제거하고 난 뒤에 전환율을 보니? 아, 모든 구간에서 체류시간 증가 -> 전환율 증가라는 큰 인사이트를 얻게 되었다.
이렇듯 Outlier 제거는 이번 데이터 분석에서 꽤나 키포인트로 작용했다.
5) (신규 + 검색 유입 + 검색 결과 페이지 경로) 유저 x (할인 / 리뷰 / 상품) 전환율 분석의 데이터 표본수가 엄청 적은거 아니냐? 😡
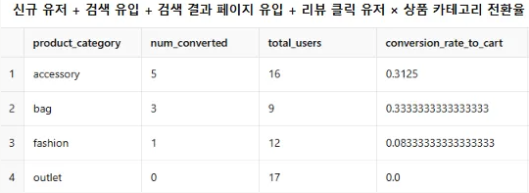
참 많이도 깊게 들어갔다.
교차 분석을 거듭할 수록 필연적으로 데이터 표본수가 적어지고, 데이터 과대해석으로 이어질 위험이 높은 것은 사실이다.
하지만 결론적으로 저 데이터는 의미가 있다.

리뷰 클릭하지 않은 데이터와 비교했을 때도, 전환율이 20% 미만으로 현저히 낮다.
하지만 리뷰 클릭시엔? 12명 중 1명, 17명 중 0명이란 극단적으로 전환율이 낮은 수치를 볼 수 있다.
모수가 늘어나도 전환율이 낮고, 그렇지 않아도 전환율이 '0%'라는 점.
과연 표본수가 저기서 늘어난다 한들 전환율이 올라갈 것인가?
단 1명도 사지 못했다면 기능적 오류가 있을 가능성도 있다. 이는 반드시 Pain Point로 잡아야 한다는 생각이 들었다.
이외에도 노션 링크를 보면 본인이 이번 과제 이 악물고 한 것을 볼 수 있다.
PRD 및 와이어 프레임, Jira를 통한 스케줄링, MoSCoW, 사용자 여정도, 유저 페르소나, 유저 스토리 등.. 최대한 모든 것을 활용했다.
진짜 열심히 했다.
위에 작성한 내용말고도 여쭤보고 싶은게 있으시다면 댓글로 남겨주시면 상세히 답변드리겠습니다,,
이번 과제, 열과 성을 다했다.
우수 과제 안 주면 운다.

'PM' 카테고리의 다른 글
| [내일배움캠프] PM - 기획 실무 문서 작성 (0) | 2025.05.01 |
|---|---|
| [내일배움캠프] 킥오프란? (1) | 2025.04.30 |
| [내일배움캠프] 서비스 기획 심화 - 데이터의 이해와 분석 정리 (0) | 2025.04.29 |
| [내일배움캠프] PM - JTBD와 5 Whys Framework에 대한 고찰 (0) | 2025.04.28 |
| [내일배움캠프] PM - 서비스 기획 입문 과제 피드백 (0) | 2025.04.25 |



